Multithreading Skinning on Age of Empires 3
Back at Ensemble Studios, I remember working on the multithreaded rendering code in both Age of Empires 3 and Halo Wars. At the time (2003-2004 timeframe), multithreading was a new thing for game engines. Concepts like shared state, producer consumer queues, TLS, semaphores/events, condition variables, job systems, etc. were new things to many game engineers. (And lockfree approaches were considered very advanced, like Area 51 grade stuff.) Age of Empires 3 was a single threaded engine, but we did figure out how to use threading for at least two things I'm aware of: the loading screen, and jobified skinning.
On Age3, it was easy to thread the SIMD skinning code used to render all skinned meshes, because I analyzed the rendering code and determined that the input data we needed for "jobified" skinning was guaranteed to be stable during the execution of the skinning job. (The team also said it seemed "impossible" to do this, which of course just made me more determined to get this feature working and shipped.)
The key thing about making it work was this: I sat down and said to the other rendering programmer who owned this code, "do not change this mesh and bone data in between this spot and this spot in your code -- or the multithreaded skinning code will randomly explode!". We then filled in the newly introduced main thread bubble with some totally unrelated work that couldn't possibly modify our mesh/bone data (or so we thought!), and in our little world all was good.
This approach worked, but it was dangerous and fragile because it introduced a new constraint into the codebase that was hard to understand or even notice by just locally studying the code. If someone would have changed how the mesh renderer worked, or changed the data that our skinning jobs accessed, they could have introduced a whole new class of bugs (such as Heisenbugs) into the system without knowing it. Especially in a large rapidly changing codebase, this approach is a slippery slope.
We were willing to do it this way in the Age3 codebase because very few people (say 2-3 at most in the entire company) would ever touch this very deep rendering code. I made sure the other programmer who owned the system had a mental model of the new constraint, also made sure there were some comments and little checks in there, and all was good.
Importantly, Ensemble had extremely low employee turnover, and this low-level engine code rarely changed. Just in case the code exploded in a way I couldn't predict on a customer's machine, I put in a little undocumented command line option that disabled it completely.
Age3 and Halo Wars made a lot of use of the fork and join model for multithreading. Halo Wars used the fork and join model with a global system, and we allowed multiple threads (particularly the main and render threads) to fork and join independently.
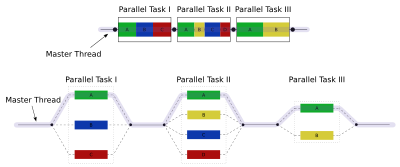
See those sections where you have multiple tasks stacked up in parallel? Those parts of the computation are going to read some data, and if it's some global state it means you have a potential conflict with the main thread. Anything executed in those parallel sections of the overall computation must follow your newly introduced conventions on which shared state data must remain stable (and when), or disaster ensues.
Complexity Management
Looking back now, I realize this approach of allowing global access to shared state that is supposed to be read-only and stable by convention or assumption is not a sustainable practice. Eventually, somebody somewhere is going to introduce a change using only their "local" mental model of the code that doesn’t factor in our previously agreed upon data stability constraint, and they will break the system in a way they don't understand. Bugs will come in, the engine will crash in some way randomly, etc. Imagine the damage to a codebase if this approach was followed by dozens of systems, instead of just one.
Creating and modifying large scale software is all about complexity management. Our little Age3 threaded skinning change made the engine more complex in ways that were hard to understand, talk about, or reason about. When you are making decisions about how to throw some work onto a helper thread, you need to think about the overall complexity and sustainability of your approaches at a very high level, or your codebase is eventually going to become buggy and practically unchangeable.
One solution: RCU
One sustainable engineering solution to this problem is Read Copy Update (RCU, used in the Linux kernel). With RCU, there are simple clear policies to understand, like "you must bump up/down the reference to any RCU object you want to read”, etc. RCU does introduce more complexity, but now it’s a first class engine concept that other programmers can understand and reason about.
RCU is a good approach for sharing large amounts of data, or large objects. But for little bits of shared state, like a single int or whatever, the overhead is pretty high.
Another solution: Deep Copy
The other sustainable approach is to deep copy the global data into a temporary job-specific context structure, so the job won't access the data as shared/global state. The deep copy approach is even simpler, because the job just has its own little stable snapshot of the data which is guaranteed to stay stable during job execution.
Unfortunately, implementing the deep copy approach can be taxing. What if a low-level helper system used by job code (that previously accessed some global state) doesn’t easily have access to your job context object? You need a way to somehow get this data “down” into deeper systems.
The two approaches I’m aware of are TLS, or (for lack of a better phrase) “value plumbing”. TLS may be too slow, and is crossing into platform specific land. The other option, value plumbing, means you just pass the value (or a pointer to your job context object) down into any lower level systems that need it. This may involve passing the context pointer or value data down several layers through your callstacks.
But, you say, this plumbing approach is ugly because of all these newly introduced method variables! But, it is a sustainable approach in the long term, like RCU. Eventually, you can refactor and clean up the plumbing code to make it cleaner if needed, assuming it’s a problem at all. You have traded off some code ugliness for a solution that is reliable in the long term.
Sometimes, when doing large scale software engineering, you must make changes to codebases that may seem ugly (like value plumbing) as a tradeoff for higher sustainability and reliability. It can be difficult to make these choices, so some higher level thinking is needed to balance the long term pros and cons of all approaches.
But, you say, this plumbing approach is ugly because of all these newly introduced method variables! But, it is a sustainable approach in the long term, like RCU. Eventually, you can refactor and clean up the plumbing code to make it cleaner if needed, assuming it’s a problem at all. You have traded off some code ugliness for a solution that is reliable in the long term.
Conclusion
Sometimes, when doing large scale software engineering, you must make changes to codebases that may seem ugly (like value plumbing) as a tradeoff for higher sustainability and reliability. It can be difficult to make these choices, so some higher level thinking is needed to balance the long term pros and cons of all approaches.
No comments:
Post a Comment